
Introduction
One challenge every enterprise faces in its data and AI journey (and we did too) is: what do you do with audit data that never stops growing?
Audit data is not just inserts, updates, and deletes-it’s the digital trail that captures who did what, when, where, and how. That includes movements, approvals, state changes, user actions, and system events. Multiply this by thousands of users and years of retention, and you end up with billions of rows and terabytes of history that are rarely touched outside compliance checks.
In our case this was Oracle EE + RAC, but the same issue exists in SQL Server, PostgreSQL, and even managed cloud databases - audit data grows much faster than transactional data
By default, most of this lands in premium databases, consuming licensing, CPU, and enterprise storage-even though it's mostly 'write once, read rarely'. At some point we had to ask: "Why are we paying enterprise-grade database prices for data we only open during audits?"
What is Audit Data?
Audit data is the end-to-end trace of activity in your systems
- Who performed the action
- What action was taken
- When it happened (timestamp)
- Where it originated (IP / host / location)
- How it was executed (API/UI/batch, tool, client)
Example: User "John" updated a customer's address in the CRM on 16 Sep 2025 at 2:30 PM, from IP 10.0.1.12.
The Problem: Audit Tables Gone Wild (Across Databases)
- Our Case (Oracle Licensed): Oracle Enterprise Edition with RAC is licensed per CPU core. As audit tables expanded, CPU usage rose and increased license exposure.
- Other DB/Infra Models: SQL Server, PostgreSQL, or managed cloud DBs scale differently - costs rise with provisioned storage and IOPS. Enterprise SAN/NAS typically runs $1,500-$3,000 per TB/year, so audit data inflates infra bills disproportionately.
- Universal Impact: Regardless of platform, multi-terabyte audit tables mean longer backups, slower queries, replication lag, and higher DBA/admin effort.
These growing datasets often impact data and AI efficiency when managing analytics workloads.
The Shift: Cloud-Native Architecture
We redesigned the pipeline to keep compliance intact while enabling data analytics and AI driven insight without the overhead of traditional databases. The architecture is tiered, automated, and cloud-native, supporting scalable data analytics and artificial intelligence environments.
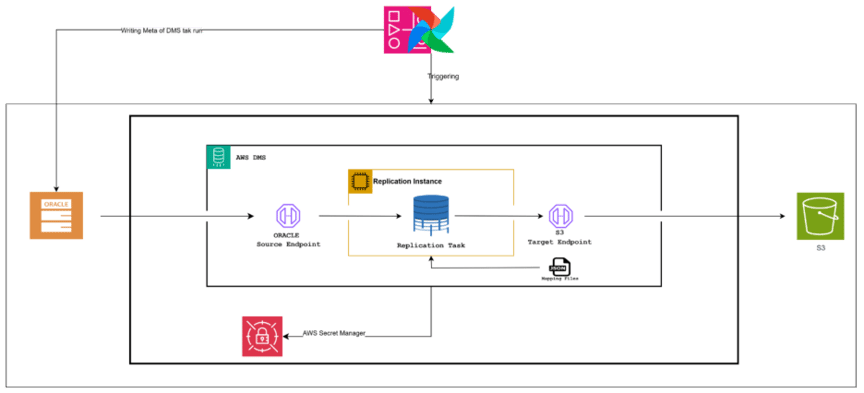
- Migration via AWS DMS → Land audit data to Amazon S3 (Parquet/Delta). DMS tasks & endpoints are codified with AWS CloudFormation.
- Tiered Storage → Recent data in S3 Standard for fast access; older partitions transition automatically to Glacier Deep Archive.
- Business-Aligned Partitioning → Quarterly partitions (and date columns) minimize scan and speed up queries.
- On-Demand Queries → Databricks external tables query S3 directly; clusters spin up only during audit windows.
Read now: How to build a successful cloud migration strategy
Figure 1A: DB-centric Audit Storage (Oracle)
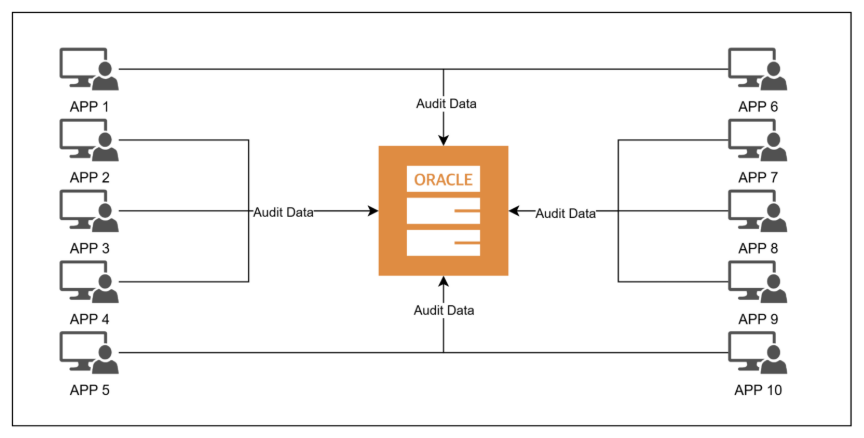
Figure 1B: Cloud-Native Audit Storage (DMS +AWS S3 + Glacier + Databricks)
Cost & Benefits (10 TB Dataset)
Below is a transparent cost model for 10 TB of audit data. Totals include storage, minimal DMS runtime, and Databricks compute used during audits.
Oracle (Licensed): CPU-core based licensing (e.g., 8-16 cores EE + RAC) was our dominant cost. Audit growth pushed up CPU demand and license exposure.
Other DB Infra: In SQL Server, PostgreSQL, or RDS-style DBs, storage costs scale by TB. Mid-range SAN/NAS typically runs $1,500-$3,000 per TB/year. Audit data grows faster than business data, inflating infra, backup, and DR costs.
Cloud (After): ~3 TB stored in S3 Standard, ~7 TB in Glacier Deep Archive. DMS used for migration, Databricks clusters spun up only for audits.
Figure 2: Annual Cost Comparison (10 TB Audit Data)
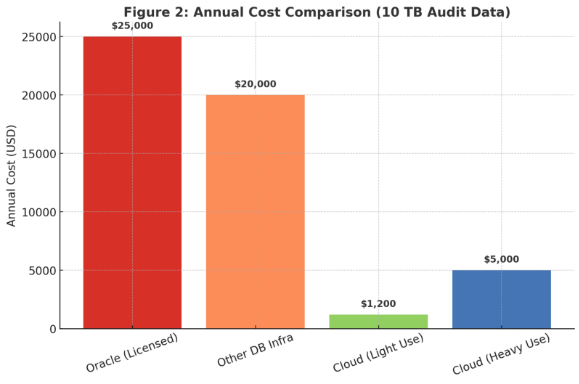
Assumptions for Figure 2:
- Region: us-east-1. DMS, S3, and Databricks in the same region → $0 data transfer.
- Storage mix: 3 TB in S3 Standard, 7 TB in Glacier Deep Archive.
- DMS: Replication instance used for initial migration and quarterly refresh (~$20/yr ongoing). Initial one-time excluded.
- Databricks: In practice, SQL warehouse or small interactive clusters cost ~$2-3/hr depending on config.
- Light: 50 hrs/yr ≈ $100-150/year.
- Heavy: 200 hrs/yr ≈ $400-600/year.
Data Security & Encryption in the Cloud
As enterprises modernize data and AI ecosystems, security and compliance remain non negotiable. When moving audit data out of Oracle (or other enterprise databases) into S3 is: how do we ensure the same-or strong levels of security and compliance?
Our design included multiple layers of protection:
Encryption at Rest:
- All audit data in S3 is encrypted using SSE-KMS (AWS Key Management Service) with customer-managed CMKs.
- Glacier Deep Archive inherits the same encryption automatically.
- This approach lets us control key rotation, audit key usage, and align with corporate compliance policies.
Encryption in Transit:
- Data migrated via AWS DMS is encrypted using TLS 1.2+.
- Queries from Databricks to S3 also use secure HTTPS endpoints, ensuring no plaintext data ever moves across the wire.
Access Controls:
- Fine-grained IAM policies ensure only the DMS role, lifecycle automation role, and specific Databricks clusters can access the S3 bucket.
- Bucket policies are locked down to specific VPC endpoints, blocking public access completely.
Auditability:
- CloudTrail + S3 Access Logs track who accessed audit data, when, and from where extending the very audit principles we are preserving.
- KMS key usage is logged, giving full traceability for compliance.
Optional Data Masking / Tokenization:
- For highly sensitive audit attributes (e.g., PII in user actions), tokenization or column-level encryption can be applied before landing in S3.
Outcome: Security posture is actually stronger than the Oracle baseline-data is encrypted end-to-end, access is tightly controlled and monitored, and compliance teams get immutable audit trails on top of the audit data itself. This strengthens the reliability of data and AI for long-term scalability.
How Securely is the Data Being Accessed
- Controlled Entry Point - Audit data in S3 is never exposed directly. All queries go through Databricks External Tables in Unity Catalog, ensuring a governed access layer.
- Role-Based Permissions - Fine-grained ACLs in Unity Catalog restrict access by persona (e.g., auditors, DBAs, compliance officers). Users only see data they are entitled to.
- Column & Row-Level Security - Sensitive fields (such as PII) can be masked, tokenized, or filtered. Views provide anonymization for compliance scenarios.
- Secure Connectivity - Users connect via TLS-encrypted JDBC/ODBC or HTTPS sessions. Mutual TLS (mTLS) can be enabled for stronger authentication.
- No Direct S3 Access - Individuals do not receive raw bucket credentials. All access flows through Databricks, ensuring policy enforcement.
- Access Logging - Every query is logged in both Databricks audit logs and AWS CloudTrail, providing a verifiable record of who accessed what, when, and how.
Alternatives & Trade‑offs
- Oracle GoldenGate - Real-time CDC replication; ideal when you need continuous audit log replication (fraud detection, ops monitoring). High license + infra cost.
- Amazon Athena - Serverless SQL on S3; cheapest and simplest for occasional ad-hoc audit queries. Struggles with very large joins/multi-TB datasets.
- Redshift Spectrum - Extend Redshift queries to S3. Best if your EDW already runs on Redshift and you want seamless integration.
- Snowflake External Tables - Query S3 (or other object stores) directly via Snowflake. Strong BI ecosystem if Snowflake is already in place.
- Stay in Database (Oracle/SQL Server/Postgres) - Only makes sense if audit data is part of day-to-day OLTP/reporting, which is rare. Costs balloon with scale.
- Our Approach (AWS DMS + S3 + Glacier + Databricks) - Best balance for compliance driven audit data:
- Low cost via tiered storage.
- On-demand compute for audits.
- Databricks External Tables = game changer: schema-on-read, no duplicate storage, and direct SQL queries on S3.
- Automation (CloudFormation + DMS).
- Scales without infra lock-in.
Lessons Learned
- Partitioning is non-negotiable: quarterly partitions cut scan cost and time dramatically for AI and data analytics workloads.
- Automate everything: CloudFormation for DMS endpoints, tasks, IAM, and lifecycle rules prevent drift and supports scalable data and AI pipelines.
- Balance hot vs cold: keep recent quarters in S3; push older data to Glacier; plan Glacier restore SLA for deep history.
- Right-size compute: run Databricks only during audits; use external tables to avoid data copies.
Conclusion
Audit data never stops growing - whether in Oracle, SQL Server, PostgreSQL, or any other platform. By offloading to S3/Glacier and enabling on demand AI and data analytics with Databricks, we preserved compliance, improved performance, and reduced cost by ~70%. The result is a repeatable, cloud-native blueprint: compliant, affordable, and database-agnostic.
