Your business is bound to have run-ins with defaulters. These defaults could be over late payment and non-payment issues and should be resolved quickly, as they can negatively impact your profit margin. At the same time, if you handle this situation without much tact, it could ruin the relationship with your customer.

Here’s where machine learning comes in – enabling customers to understand the patterns that defaulters follow and find the means to prevent them. Some time ago, we worked with a large power distribution company that collects payments from around three million consumers every month.
Challenging collection efficiencies
This utility company closely monitors the percentage of invoice amount recovered on time or in advance as a key metric. They were keen to improve their existing collection efficiency, which worked out to 78 per cent.
However, the numerous areas that influenced the collection efficiency such as billing cycles, multiple invoicing and disparate data sources were difficult to interpret. Traditional BI tools were limited in their ability to help gain a deeper understanding of all the areas. Deploying machine learning techniques was, therefore, a natural choice.
Analysis of existing data
We reviewed data from various sources of around 450K consumers who were on a commercial tariff plan. The data parameters we covered included usage and payment, demographics, nature of business, bill distribution agency and the modes of payment.
These datasets were combined with external information such as seasons, festivals, holidays and the like. Open source platforms such as Python and various libraries within Python to prepare the data, deliver exploratory analysis and predictive modelling were used.
Customer Segmentation
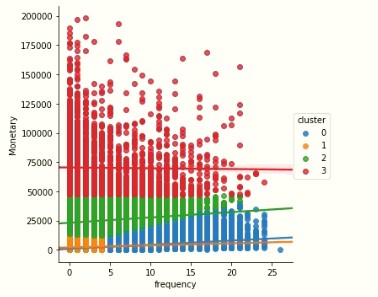
Customers with similar usage patterns and (late/non) payment were considered a segment. We created non-hierarchical clustering algorithms in machine learning to identify the optimum number of segments and criteria for segmentation as detailed in the figure below.
Propensity Modelling
We wanted to predict the likelihood of each customer defaulting on bill payments in the next month - by applying various classification algorithms to derive stable models (one per segment). Further, we used time-sliced sampling to prepare training and test datasets. Additionally, we conducted back-testing on three months of data to improve model accuracy.
Actionable Insights
We gleaned some valuable information from the data. For instance, in customer segments with frequent defaults (an average of eight within the last two years), the behaviour correlated with the billing month. These customers usually defaulted once every quarter. About 25 per cent of customers fall in this segment and account for 50 per cent of defaults by value.
Whereas in segments with regular payers, defaults occur just once every two years. This happens when the bill amount exceeds the individual’s average by 50 per cent or more. Nearly 300K customers in this segment account for 25 per cent of the default by value. For customers with a regular high usage - about 10 times higher than the average customer, defaults correlate with cash flow trends in the type of business they run.
The road to recovery
The model that we developed using machine learning delivers an accuracy rate of 70 per cent. It can also be retrained to discover new patterns that emerge when fresh data is supplied.
The collections team at this utility company now has a clear direction on the action plan for specific customer segments. They can adhere to their collection targets while also maintaining a good relationship with the customer.
Connect with us to learn more about how our business intelligence solutions can help your enterprise improve business agility by predicting customer behaviour.
